HW 3 - Note there are 3 parts (7 methods)
Part 1 - a Binary Search Tree of DJIACompany objects
In HW 2 we used a sorted linked list to store DJIACompany objects. This time, we're going to use a Binary Search Tree, which also keeps its contents sorted. In fact, Binary Search Trees are only useful if their contents are sorted. We will use the company ticker symbols as the criteria (A-Z) for sorting our objects.
Download and open the following 4 files:
Go through the code of these classes and read the documentation. The DJIATreeFrame has a main method. This time our application will render your DJIABinarySearchTree. I have provided a method that works properly for adding nodes to your BST. The problem is that it cannot forecast the order with which data will be given to it, and so we may quickly end up with a gangly, inefficient BST that is deeper than it needs to be.
As we discussed in lecture, it is important to keep Binary Search Trees (BSTs) as shallow as possible, to ensure searching is efficient. After all, a primary benefit of using BSTs is the log(n) search efficiency.
YOUR TWO METHODS, ALL FROM THE DJIABinarySearchTree CLASS
- Define the
calculateTreeLevelsmethod such that when called it dynamically calculates the number of levels in the tree. This means it should return the level of the deepest node. I am using this method to help in the rendering of the tree. - Define the
rebalancemethod so that when called it reconfigures the tree such that the tree depth is minimized and such that your BST equally balances left & right nodes (note, this is not necessarily a complete tree).
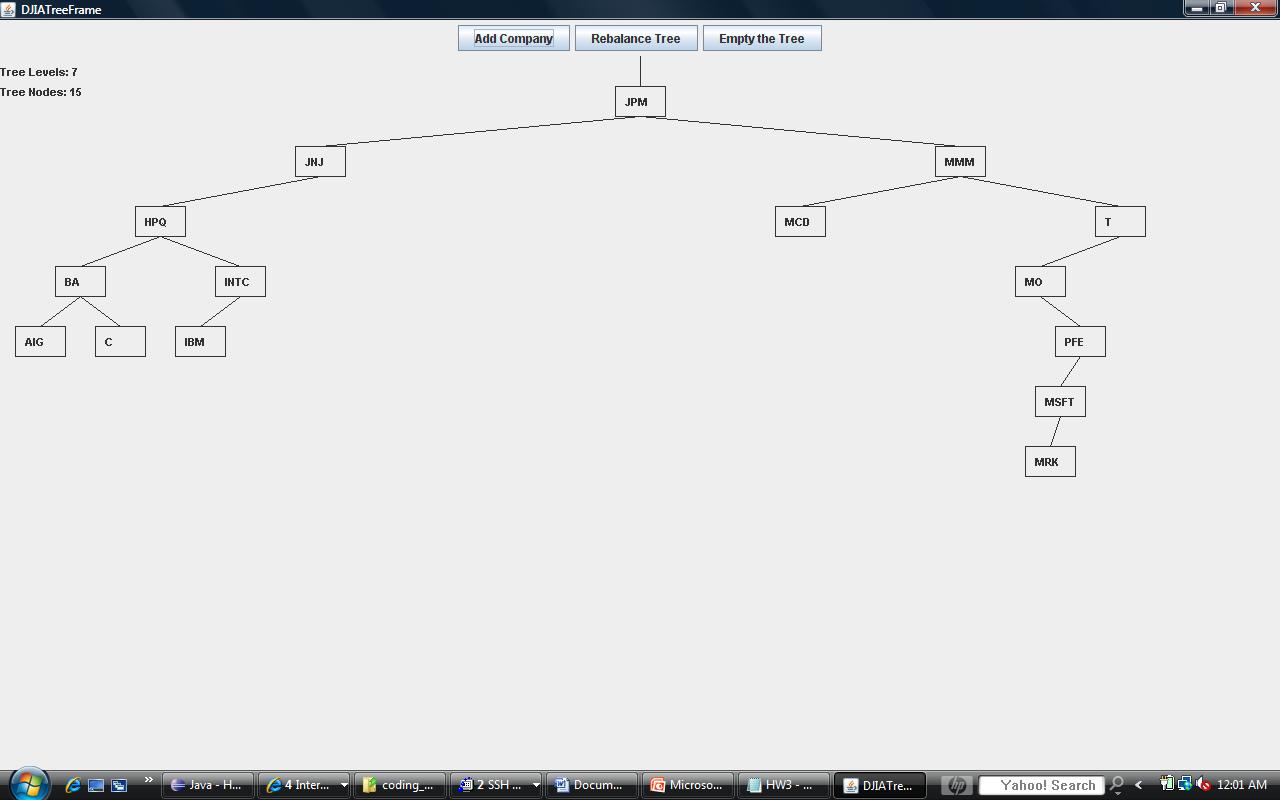
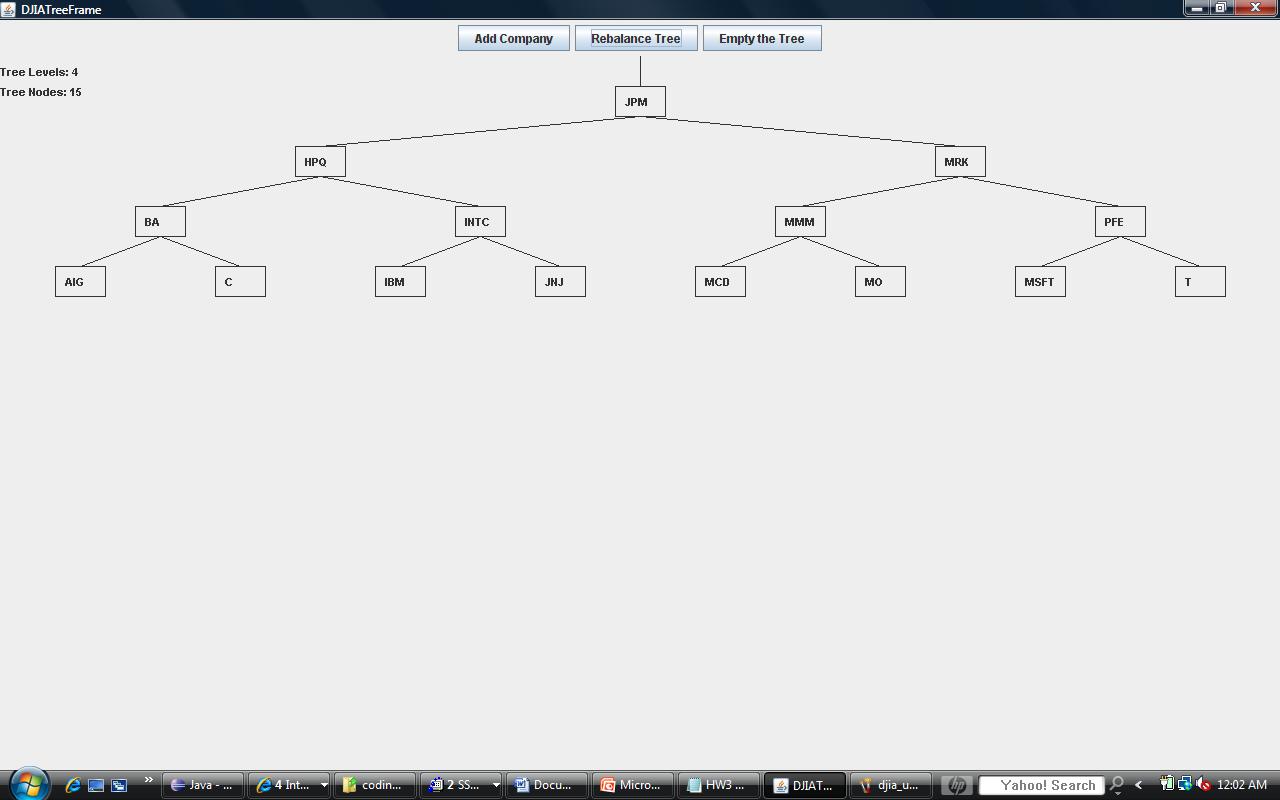
Should you implement your methods properly, for the input I've provided in the file, you should get trees that look like the ones provided in the images below. The first one is after all 15 nodes have been added. The second one is after calling your rebalance method. Note that my file only has 15 companies because adding more results in a seriously fugly tree. There just isn't enough space to render it neatly, but that's ok, we get the point with 15 nodes.
Should you load all 15 DJIA elements into the tree it should look like:
If you then rebalance the tree, it should look like:
Part 2 - using an array-implemented tree to manage a tournament
In class we mentioned how a complete tree, or better yet, a full tree, can be managed very efficiently using an array rather than node objects. That's what we'll do in this part. In the NCAA Men's Basketball Tournament, 64 teams compete for one championship title. A bracket for such a tournament would logically be managed by a full tree data structure. Due to space constraints, we'll only manage a tournament of 8 College Basketball teams. For this part, I have provided the following 3 files:
The TournamentBracketFrame class has a main method that simply opens up a GUI, loads your tree with data concerning the 8 teams in the tournament, and handles user input. The GUI only has one button, which each time you press it should produce random results weighted by team records for all tournament games.
To do this, you will manipulate the tree, which stores all of its data in an array similar to the technique we discussed in lecture. I have defined the initTeams method, which takes an array of Teams (size should be a power of 2), and places its contents into our tree-array, putting them into the indicices representing the tree leaves. All parent nodes, including the root, start out storing null, the reason is we don't know who's going to win the tournament yet, only the teams entering, and based on the order they are given, who each team's opponent will be in the first round. You will have to write code that fills in the tournament bracket with results.
YOUR THREE METHODS, ONE IN THE TournamentBracketManager CLASS:
- Define the
runTournamentmethod such that when called, it fills in the entire bracket with tournament results. Games should be determined simply by calling theplayGamemethod, which is a weighted method for randomly selecting a winner in a game between two team arguments. Note that you should update the records of the teams as the tournament games are played.
HINT: Remember how we talked about pre, in, and post order traversal in a tree and the differences between them. Note that post order traversal means that parent node data is processed after its children's node data is processed. This seems a natural fit for this problem, since we can't compute the tournament winner until we know who has won in the previous rounds.
AND TWO IN THE BottomUpBracketIterator CLASS:
- Define the
hasNextmethod such that it aids in an Iterator's production of elements in the order of leaves to root. - Define the
nextmethod such that produces the nodes in the tree in the order of leaves to root (bottom-up).
Note that the BottomUpBracketIterator is being used for rendering. It needs to produce the elements in the correct order, left to right, bottom level frist, and should do so whether the tree has 8 teams, 64 teams, 128 teams, etc. You will have to think about this problem mathematically. Understand that you should probably add instance variables to your BottomUpBracketIterator class such that it knows which index is "next" (or current if you prefer). This stored index would then be used to produce elements when the next method is called. Be aware, of course, that elements are not being produced from the array from 0 thru length-1, but rather taking the tree structure into account, in the order of bottom nodes first, top nodes (like the root) last.
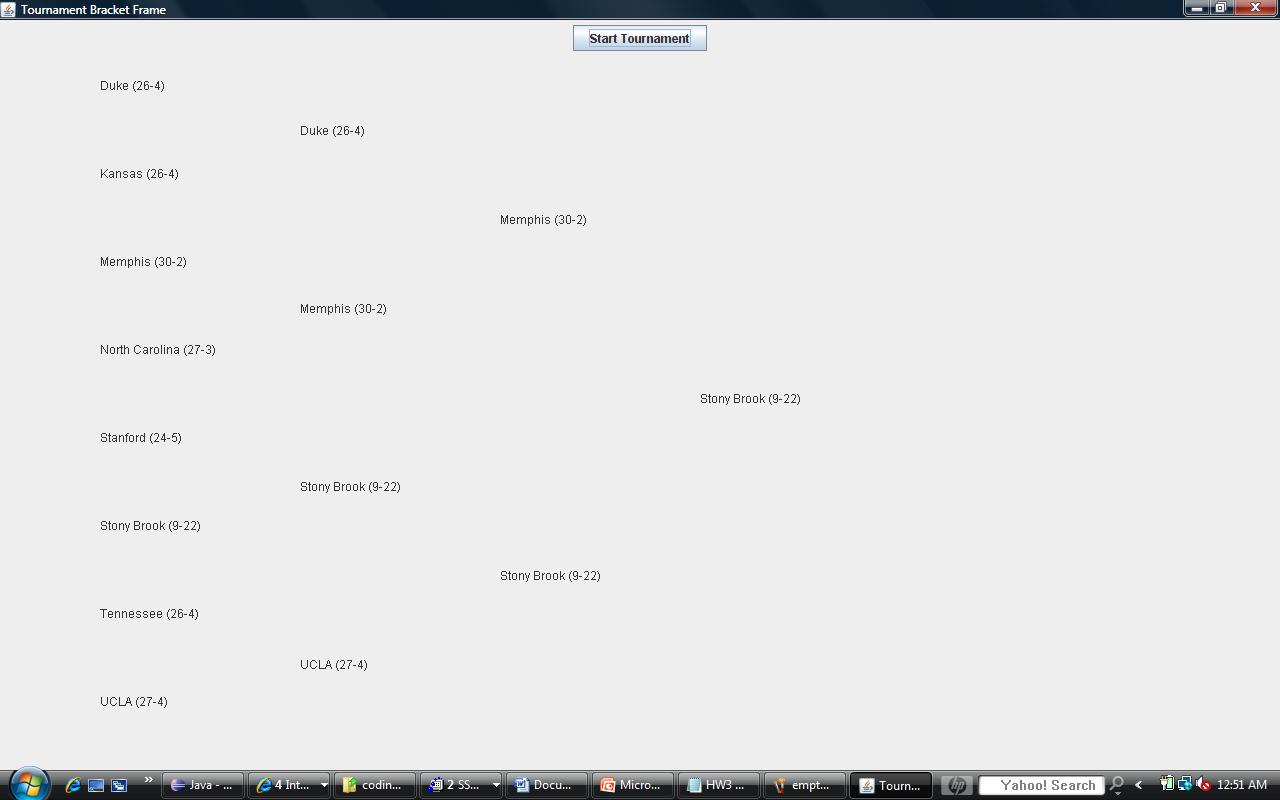
If you implement your methods properly, when your program first starts up it should look like:
![]()
After running the tournament once, it might look like:
Part 3 - using Trees to parse HTML
HTML is a very simple language. It is not a programming language (it has no logic or instructions). It is a markup language, using tags (like <p>) to define the structure and content of a Web page. The structure of an HTML document (as well as XML), is hierarchical. Tags are placed inside of other tags, to denote relationships between different page components. Becauase of this, Web Tools (like Browsers) store Web page documents like HTML & XML files in trees. In this part, we are going to build Web pages (HTML) by manipulating trees. For this part, I have provided the following 1 file:
The HTMLFrame class has a main method that opens up a GUI and uses a Jtree to display the contents of a tree that stores an HTML document we may wnat to build. Note that we will never load or save our HTML document, just view it using the preview button. The GUI has buttons to allow us to add node, remove nodes, and change the contents of nodes.
The Java API has a number of classes for storing and manipulating trees, but 3 interest us for this part of the assignment: DefaultTreeModel, which is a tree-managing class, DefaultMutableTreeNode, which is a tree node class, and TreePath, which stores an array of objects representing a path to a node.
YOUR TWO METHODS, ALL FOR THE HTMLFrame CLASS
- Define the
initTreeDatamethod so that it adds nodes to thetreeManagersuch that it forms a starting point for making Web pages. Such a starting point would have the necessary tags to make any Web page: html, head, title, and body, as well as a couple of example content tags. In order to do this, you are going to have to construct nodes and then insert them into the tree model properly (useinsertNodeInto). Note that there are methods for adding nodes to other nodes in the node class, but you should use the one in the tree-managing class because it does some other stuff like updates important instance variables that maintain information about the tree. - Define the
generateHTMLTextmethod such that when called, constructs and returns aStringobject representing a Web page by combining the contents of all the tree's nodes. For this you'll have to carefully walk the tree in the proper order and build your text.
NOTE: Note that when a tree has been update, to ensure the changes are immediately displayed we have to call the JTree's scrollPathToVisible method, which takes a tree path argument. A tree path can be constructed using the path of nodes provided by the node you want to make visible. For example, to make the titleTextNode visible, we might write:
tree.scrollPathToVisible(new TreePath(titleTextNode.getPath()));
NOTE: Your nodes should be storing text. Either tag text (like <body>), or content text, which humans will acutally read in a Web browser. Your nodes do not have to store HTML closing tags, but your generateHTMLText method needs to include them when generating the Web page text.
Should you implement your tree initialization properly, when the program starts it should look like:

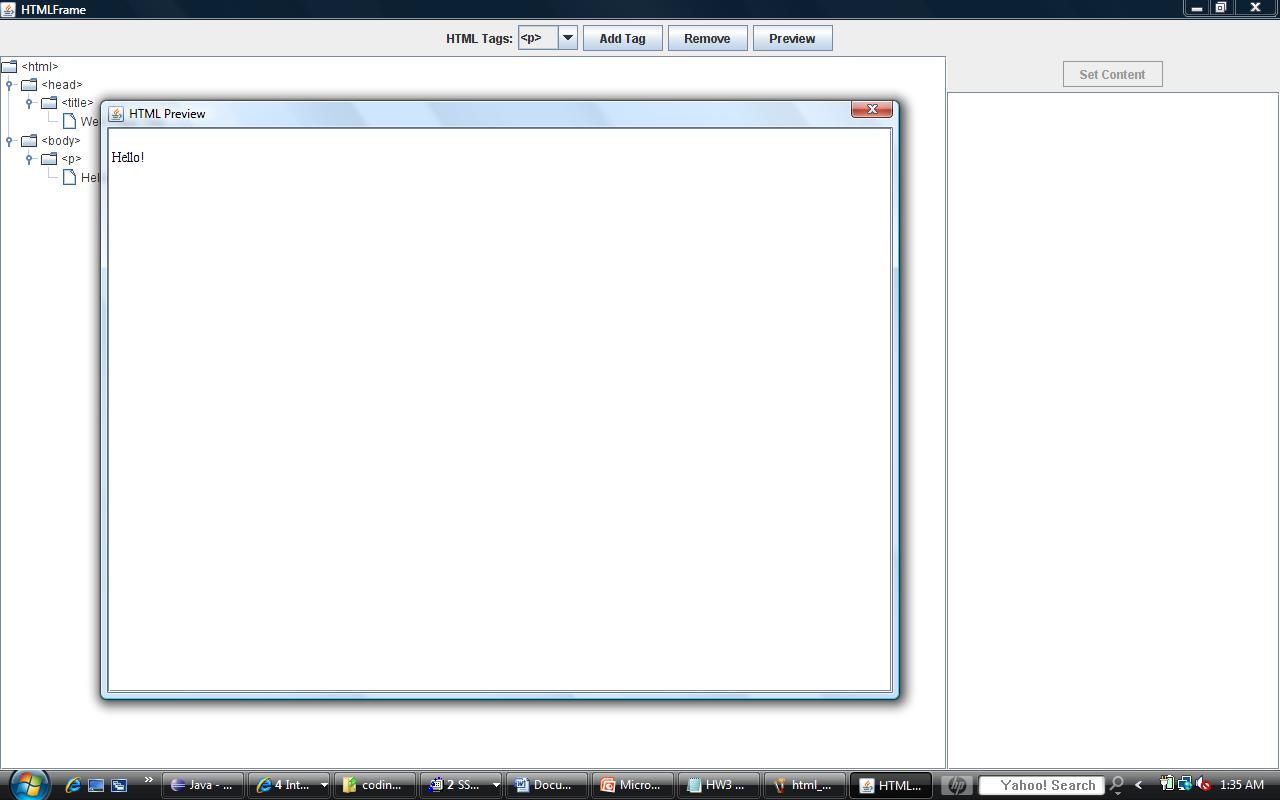
Should you click on the "Preview" button, it should open a dialog that looks like:
HANDIN INSTRUCTIONS
For this and all future assignments, work should be handed in using your Sparky account. To do so, you should use SSH (you may download it for free from SoftWeb), which is found on all SINC site computers. Go to the HW Handin Instructions Page for details on how to hand in your work.

 Web page created and maintained
Web page created and maintained
by Richard McKenna